
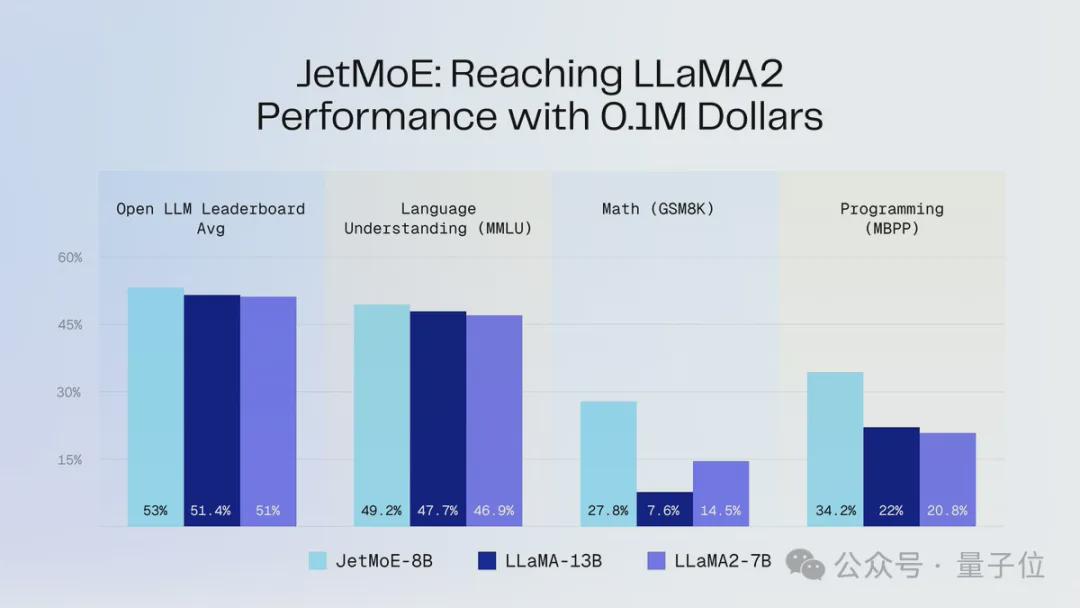
最近,一款名为JetMoE的新型MoE模型在人工智能领域引起了轰动。这款模型由MIT、普林斯顿等研究机构联合打造,性能媲美甚至超越了同等规模的Llama-2。而最令人惊讶的是,仅需10万美元的投入就能训练出这样一款高性能的大模型。
JetMoE的发布完全开源,并且采用学术界友好的方式,只使用公开数据集和开源代码,即可在消费级GPU上进行微调。这种低成本高性能的模型打造方式,让人们重新审视了大模型的训练成本。

JetMoE的灵感来源于ModuleFormer的稀疏激活架构,其中包含24个区块,每个区块包含2个MoE层,分别是注意力头混合(MoA)和MLP专家混合(MoE)。每个MoA和MoE层又包含8个专家,每次输入token激活2个,共有80亿参数。

在训练过程中,JetMoE-8B使用了1.25T token的公开数据集,学习率为5.0 x 10-4,全局batch size为4M token。整个训练过程分为两个阶段,采用了MiniCPM的训练方案,最终在96×H100的GPU集群上花费了约8万美元,训练完成JetMoE-8B。
JetMoE-8B在推理过程中表现出色,仅具有22亿个激活参数,计算成本大大降低,同时性能表现优异。在8个评测基准上获得了5个sota,超过了多个大型模型,展现出了其强大的实力。
JetMoE的团队由Yikang Shen、国振(Gavin Guo)、蔡天乐和Zengyi Qin组成,他们分别来自MIT、普林斯顿等知名机构,具有丰富的研究经验和技术实力。这支华人团队在人工智能领域的领先地位得到了贾扬清等人的认可和支持。
JetMoE的成功发布标志着人工智能领域的一次重要突破,让我们拭目以待更多关于这款模型的技术细节和应用场景。更多信息请访问官方GitHub链接:https://github.com/myshell-ai/JetMoE。