
嘿,各位读者!今天我要和大家分享的是谷歌最新推出的一款神秘黑盒解锁工具——Patchscopes!这个框架不仅可以帮助我们深入理解大型语言模型(LLM)的内部运行机制,还能提供自然语言解释,让我们更轻松地修复模型的推理错误。

在过去,我们对于LLMs的不透明性和不可解释性一直颇有微词。但是现在,有了Patchscopes,我们可以通过探索隐藏表征的方式,更深入地了解模型的行为。这个框架不仅可以在自然语言处理领域和自回归Transformer模型中应用,还可以帮助我们检测和纠正模型的幻觉,探索多模态表征,甚至研究模型在复杂场景中的预测构建。
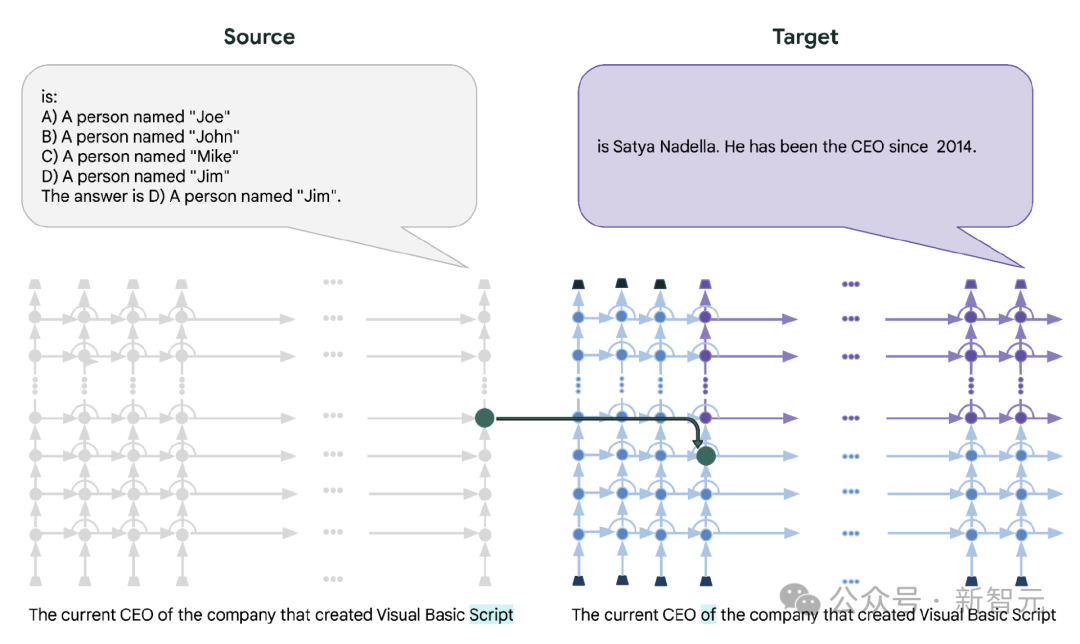
那么,Patchscopes具体如何使用呢?首先,我们需要设置一个标准提示,然后通过目标提示来提取隐藏信息。比如,在实体共同指代解析任务中,我们可以通过简单的单词重复提示来揭示隐藏表征中的信息。虽然这些单词可能看起来随机选择,但它们遵循特定的编写模式,帮助我们更好地理解模型的内部运行方式。
除了实体共同指代解析,Patchscopes还可以用于下一个token预测、提取事实、解释实体等任务。通过重新路由中间隐藏表征,我们甚至可以帮助模型修复错误推理,提高准确性。这种方法不仅可以应用于单一模型,还可以用于团队合作,让一个模型解释另一个模型的输入处理,进一步提升模型的性能。
Patchscopes为我们打开了LLM黑盒的神秘面纱,让我们更深入地了解模型的内部运行机制。通过实战教程的学习,我们可以更好地掌握这一强大工具,帮助我们解决模型的幻觉问题,修复推理错误,提高模型的性能。让我们一起来揭秘Patchscopes,探索LLM的奥秘吧!