哇,精彩精彩!Mamba架构终于迎来了第一个真正大规模的突破,推出了名为Jamba的混合Transformer模型,参数高达520亿,性能媲美Mixtral 8x-7B,吞吐量更是其3倍。这可真是绝对的“大新闻”啊!
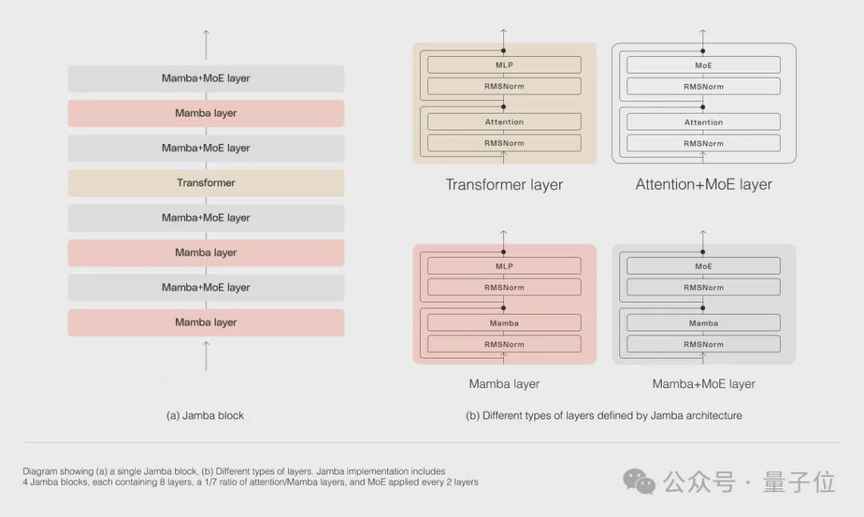
Mamba架构最初由以色列AI公司AI21labs提出,解决了Transformer模型在处理长上下文时内存占用量大、推理速度慢的问题。但是,Mamba在召回相关任务上表现不佳。为了兼顾模型质量和效率,Jamba应运而生,集成了Transformer、Mamba和MoE层,通过创新的块层组合方法,每八层一个Transformer层,同时利用MoE层增加模型参数总量,简化推理中的活动参数量,提高模型吞吐量,保证高效推理工作负载。

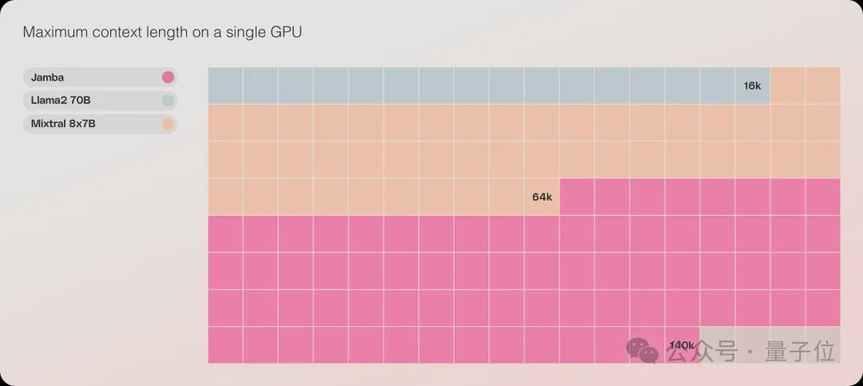
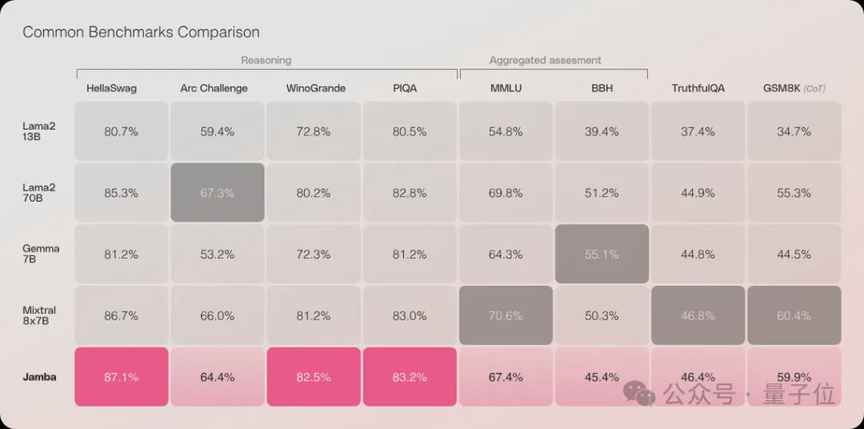
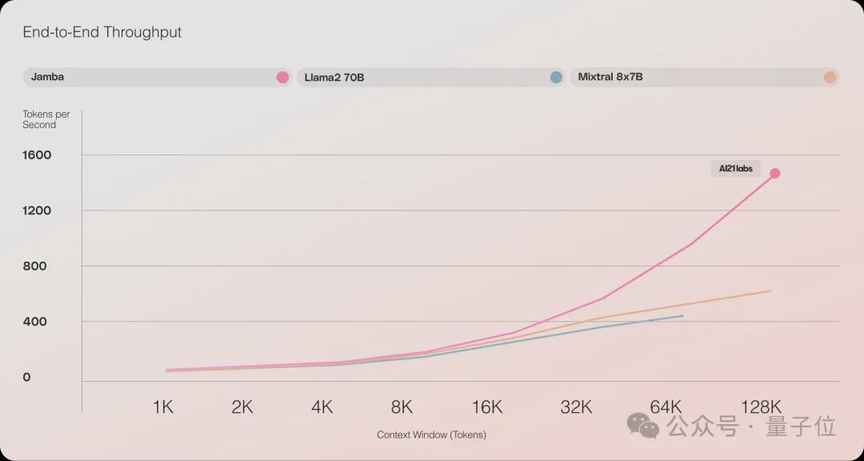
Jamba的性能表现十分出色,吞吐量高效,内存利用低。在长上下文中,Jamba的吞吐量是Mixtral 8x7B的3倍,每秒token数接近1500,远超其他同等规模的Transformer模型。在单张GPU上,Jamba最多可以容纳140k上下文,经济又高效。此外,在一系列推理基准上,Jamba取得了多项SOTA成绩,整体性能接近Mixtral 8x7B。
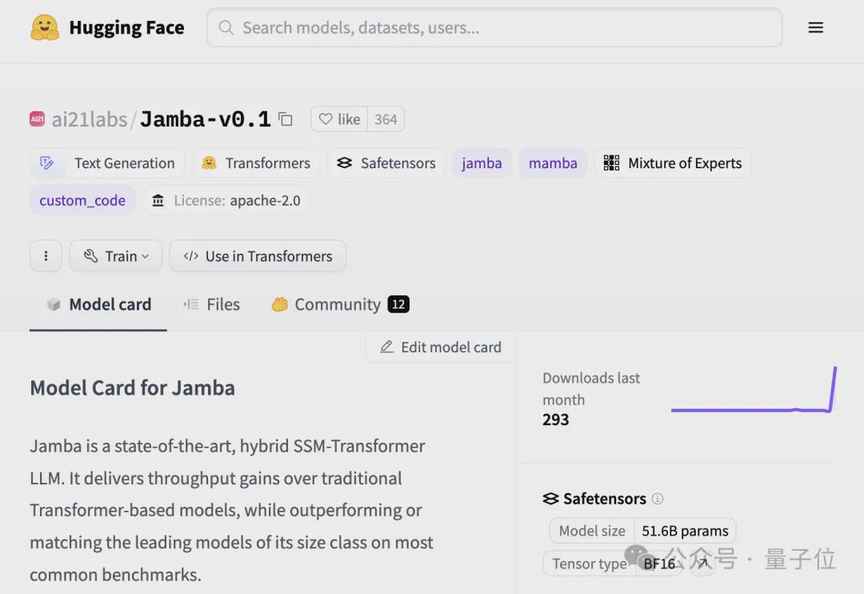
更令人振奋的是,这只是Jamba初步改造后的结果,未来还有更多优化空间,性能将进一步提升。好消息是,Jamba已经上线Hugging Face,并且采用apache-2.0许可。网友们看完都感动得哭了。想要了解更多关于Jamba的信息,可以点击传送门:https://huggingface.co/ai21labs/Jamba-v0.1。